Herline 教育底层 thesis · #7
别再问 AI 会不会替代孩子,先看他站在哪个象限
真正该识别的不是职业名称,而是任务的 AI 暴露度与互补度:右下角会被压价,右上角才会被放大。
TL;DR
教育判断不能再停留在「AI 会不会替代某个职业」。真正有解释力的是两个指标:AI 暴露度,以及 AI 互补度。高暴露、低互补的任务会被压价,例如标准通稿、普通翻译、基础代码、资料搬运;高暴露、高互补的能力会被放大,例如架构判断、复杂研究、AI-native 产品设计。教育的风险,是继续把孩子训练到右下角;教育的机会,是让孩子进入右上角或左上角:会调度 AI,也有判断力、表达力、品味和长期信任。
核心论点
- 判断一个能力是否值钱,要同时看 AI 暴露度与 AI 互补度;只问「会不会被替代」太粗
- 高暴露、低互补是风险区:标准通稿、普通翻译、基础代码、资料搬运等任务会被快速压价
- 高暴露、高互补是杠杆区:AI 深度介入,但真正定价的是人的领域判断、约束设计、审计能力和品味
- 中国教育的主要错配,是仍在投入大量资源训练标准答案、套路表达、高频刷题等右下角能力
- 教育产品要从课程证书转向双轨档案:AI 素养证据 + AI 抗体证据,让长期能力可以被未来读懂
过去几年,关于 AI 与教育的讨论常常停在一个笼统问题上:AI 会不会替代人?
这个问题太粗。它把职业当成一个整体,却忽略了职业内部的任务差异。AI 不会按「程序员」「老师」「会计」「设计师」这样的名称替代人,它会先接管一批可复制、可验证、低判断密度的任务。
教育真正该问的,不是某个职业会不会消失,而是一个孩子正在训练的能力,落在什么坐标上。
这个坐标有两个轴:
- AI 暴露度:这类任务有多少可以被模型低成本完成?
- AI 互补度:AI 介入后,是放大人的稀缺性,还是压低门槛、抹平壁垒?
先看这张图。
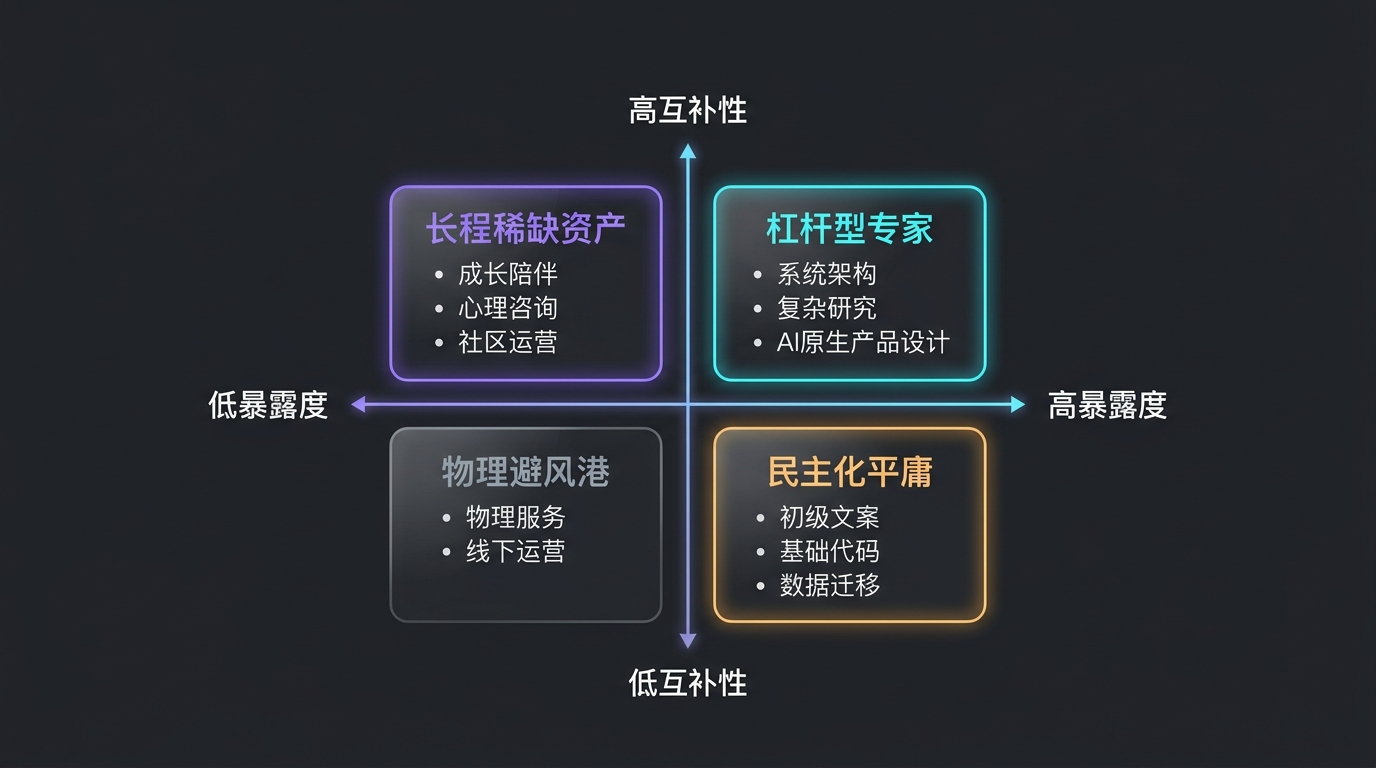
这张图就是本文的核心。
右下角,是教育要警惕的区域。 任务高度暴露给 AI,但 AI 介入后并不放大人的稀缺性,只会降低门槛、增加供给、压低价格。标准通稿、普通翻译、基础代码、资料整理、模板化内容生产,都在这个方向上。
右上角,是教育要争取的区域。 AI 深度介入工作,但产出质量仍取决于人的领域判断、约束设计、审计能力和品味。高级系统架构师、复杂研究者、AI-native 产品负责人,都不是因为远离 AI 而值钱,而是因为能用 AI 放大判断。
左上角,是人类长期稀缺资产。 它们的价值来自物理在场、长期信任、担责关系和不可压缩的经验。成长陪伴、心理咨询、复杂谈判、线下带队、真实社群经营,都属于这一类。
教育的风险,是继续把孩子训练到右下角。教育的机会,是把孩子推向右上角或左上角。
一、劳动市场已经按这个坐标重新定价
几个公开数据已经把趋势讲得很清楚。
世界经济论坛《Future of Jobs Report 2025》预测,2025-2030 年,结构性劳动市场变化将影响当前岗位总量的 22%;同时创造约 1.70 亿个新岗位、替代约 0.92 亿个岗位,净增约 0.78 亿个岗位。它还指出,现有技能中约 39% 会转变或过时;若把全球劳动力看作 100 人,约 59 人需要培训。
这组数据说明的不是「就业归零」,而是技能组合被重写。
Stanford Digital Economy Lab 的工作论文《Canaries in the Coal Mine?》给了更尖锐的信号:在生成式 AI 普及后,美国 22-25 岁早职业劳动者在高 AI 暴露岗位中出现 13% 的相对就业下降;经验更深者与低暴露岗位仍稳定或增长。下降更集中出现在 AI 偏「自动化」而非「增强」的职业。
这正好对应上面的坐标:同样是高暴露岗位,如果 AI 是在自动化基础任务,新人承压;如果 AI 是在增强专家判断,资深从业者反而可能被放大。
过去,年轻人进入行业后,可以先做基础任务:整理资料、写初稿、改格式、查数据、跑基础代码、做低风险分析。通过这些任务,他们逐步积累行业语感,再获得更高判断权。
但 AI 先接管的,往往正是这些基础任务。
Anthropic Economic Index 及基于 Claude 对话的研究也显示,AI 的真实使用已经深度进入软件开发和写作任务;约 36% 的职业至少有四分之一任务出现 AI 使用;使用形态大致分为增强与自动化两类。换句话说,AI 并不是均匀地「替代职业」,而是在职业内部重写任务结构。
这正是教育要警惕的地方:如果孩子只被训练成更快、更熟练地完成标准任务,他未来面对的竞争者,可能不再是同龄人,而是模型和会调度模型的人。
二、不要给职业贴标签,要拆开看任务
同一个专业内部,也会同时存在四个象限。
会计里的基础记账与财务判断不同;软件里的样板代码与系统架构不同;教育里的知识讲解与成长陪伴不同。AI 时代真正被重新定价的,不是专业名称,而是任务性质。
| 象限 | 典型任务 | 未来状态 | 教育含义 |
|---|---|---|---|
| 高暴露 + 高互补:杠杆型专家 | 架构设计、产品判断、复杂研究、AI-native 运营 | AI 深度介入,但产出质量仍取决于人的领域判断、审美、约束设计和审计能力 | 要训练孩子调度 AI,也训练能审 AI 的专业判断 |
| 高暴露 + 低互补:民主化平庸 | 标准通稿、普通翻译、基础代码、资料搬运、模板化商插 | 准入门槛下降,供给激增,价格被压缩;初级岗位先承压 | 不应把长期教育资源押在这类可复制任务上 |
| 低暴露 + 低互补:物理避风港 | 高现场依赖、低技能溢价的线下任务 | 短期受 AI 直接冲击较慢,但难享受 AI 杠杆,收入上限有限 | 不能把「AI 替不了」误读为「长期高价值」 |
| 低暴露 + 高互补:长程稀缺资产 | 成长陪伴、心理咨询、复杂谈判、线下带队、真实社群经营 | 价值来自物理在场、长期信任、担责关系和不可压缩的经验 | 这是 AI 抗体的核心训练区 |
这张表也解释了一个常见误判:「低暴露」不等于「高价值」。
有些线下任务短期不容易被 AI 直接替代,但如果它们无法享受 AI 杠杆,也没有积累信任、判断、品牌或资源网络,收入上限仍然有限。真正值得教育投入的,不是简单逃离 AI,而是进入能被 AI 放大的高互补区。
三、中国教育的错配:仍在训练大量右下角能力
应试训练并非没有价值。它提供纪律、基础知识和早期结构化能力。
问题在于,当教育长期停留在「标准答案 + 套路表达 + 高频刷题」层面时,就会把孩子推向 AI 擅长接管的任务区。
过去,这些能力是进入大学和初级岗位的门票。今天,门票本身正在贬值。模型可以在极低成本下生成标准作文、解题步骤、摘要、翻译和代码片段。孩子如果只被训练成「比同龄人更快完成标准任务」,他会很快发现,真正的对手不是同龄人,而是模型与会用模型的人。
更深的风险,是初级岗位变薄。
传统职业成长依赖一条隐形阶梯:新人先做基础任务,在低风险工作中积累行业语感,再逐步获得判断权。但如果基础任务被 AI 接走,年轻人就会更早被要求证明自己能做「更高一层」的事。
这对教育提出了新的要求:孩子不能等到大学毕业才开始建立能力证据。他需要更早拿出真实项目、公开表达、可追踪的 AI 工作流、跨时间的作品积累,以及能解释自己判断的能力。
这也是为什么,单纯的「AI 工具课」不够。
只教孩子使用某个大模型、某个提示词模板、某个 AI 绘图工具,本质上仍是工具操作课。工具入口会越来越便宜,模板会被快速复制,平台会不断免费化。
教育机构真正需要做的,不是把旧课程外面包一层「AI 工具」,而是把课程目标改成:用 AI 逼出更高密度的判断、表达、复盘和真实交付。
四、未来孩子需要的,不是单边「AI 素养」
未来教育要培养的能力,至少有两条轴。
第一条轴是 AI 素养。它不是会打开工具,而是能把模型变成个人杠杆。
一个有 AI 素养的孩子,应该会拆任务、分配工具、设定检查点;会给模型足够上下文、边界、反例和验收标准;会识别幻觉、遗漏、偷换概念和低质量结论;也能在新工具出现后,快速判断它对自己的真实价值。
第二条轴是 AI 抗体。它不是反 AI,而是不被 AI 替代的免疫力。
AI 抗体对应四类长期资产:判断力、表达力、品味、定力。
判断力,是在不完整信息中排序、取舍、担责。表达力,是让真实的人愿意听、愿意信、愿意行动。品味,是长期接触高质量材料后形成选择标准。定力,是能在一个方向上持续投入,并在真实关系中形成长期信任。
这两条轴缺一不可。
只有 AI 素养,没有 AI 抗体,孩子会跑得很快,但杠杆放大的可能只是浅层输出。只有 AI 抗体,拒绝 AI 杠杆,孩子也可能被同样有判断力、但更会调用工具的人超过。
真正稀缺的是两者结合:会调度 AI 的人,同时也是能做判断、能表达、能被信任的人。
五、教育产品要从证书,转向双轨档案
未来雇主、学校、合作方和社群,会越来越少只看「你说自己会什么」,而会看「你长期做成过什么」。
因此,教育产品要从课程结业证书,升级为能力证据系统。
| 链路 | 留下的证据 |
|---|---|
| 输入:书、议题、真实问题 | 孩子处理过什么真实材料和真实问题 |
| AI 工作流:拆解、检索、生成、审计 | 孩子如何调度 AI,如何设置检查点 |
| 判断产物:观点、方法、方案、反证 | 孩子是否形成自己的判断,是否能解释理由 |
| 表达产物:演讲、文章、展示、课程、作品集 | 孩子能否把判断交付给真实受众 |
| 真实反馈:老师、同伴、家长、公开受众 | 孩子如何面对反馈并修正 |
| 双轨档案:AI 素养证据 + AI 抗体证据 | 未来能读懂的长期能力记录 |
这套档案的价值,不在于包装漂亮,而在于可追踪。
别人能看到孩子如何调用 AI,如何纠错,如何形成判断,如何面对真实反馈,以及这些能力如何跨时间复利。
这意味着教育产品要做四个结构性调整。
第一,从「教知识点」转向「交付真实任务」。知识点仍然重要,但知识点必须进入任务。一个孩子读完一本书,不应只回答选择题,而应能产出观点卡、演讲、视频、展示稿或一个能被他人使用的小型方案。
第二,从「评分结果」转向「过程证据」。AI 时代,答案本身会越来越便宜。真正能区分孩子能力的,是中间过程:他怎么拆问题,怎么问模型,怎么核验事实,怎么修正方向,怎么解释自己的选择。
第三,从「老师讲得好」转向「老师能陪伴判断形成」。标准化讲解会被 AI 快速压价。老师的高价值部分会迁移到三个位置:发现孩子真正的问题,陪孩子把模糊判断变清楚,在长期互动中建立信任与责任感。
第四,从「短课包」转向「长程档案」。如果一个能力需要被未来读懂,它就不能只靠一次考试证明。表达、品味、判断、定力,都要在多个任务、多次反馈、多个真实场景里留下连续证据。
结语:教育要把孩子推向「判断主体」
AI 不是让教育失去意义,而是让教育中低判断密度的部分失去溢价。
未来仍然需要会写作、会编程、会研究、会表达的人;但市场会更少奖励「能完成标准任务的人」,更重视「能定义问题、调度工具、做出判断、承担结果、被他人信任的人」。
教育的答案不是让孩子躲开 AI,也不是把孩子塞进工具课,而是让孩子尽早形成双轨能力:
戒掉右下角路径:只练标准任务、只追求答案速度、只学工具按钮。
转向右上角与左上角:
- 用 AI 素养获得杠杆;
- 用 AI 抗体守住稀缺性;
- 用双轨档案把能力沉淀成别人看得见、查得到、能长期复利的证据。
这就是我们这一代教育者必须回答的问题:当 AI 可以完成越来越多任务时,孩子身上还有什么,是值得被长期信任、长期选择、长期追随的?
资料来源
| 来源 | 链接 | 本文引用用途 |
|---|---|---|
| World Economic Forum, The Future of Jobs Report 2025 | weforum.org/publications/the-future-of-jobs-report-2025/digest | 2025-2030 岗位结构变化、技能变化、再培训需求 |
| Stanford Digital Economy Lab, Canaries in the Coal Mine? Six Facts about the Recent Employment Effects of Artificial Intelligence | digitaleconomy.stanford.edu/publications/canaries-in-the-coal-mine | 早职业劳动者在高 AI 暴露岗位中的相对就业下降、自动化/增强差异 |
| Anthropic Economic Index | anthropic.com/economic-index | AI 真实使用形态与经济影响追踪入口 |
| Handa et al., Which Economic Tasks are Performed with AI? Evidence from Millions of Claude Conversations | arxiv.org/abs/2503.04761 | Claude 对话映射到职业任务、增强/自动化比例、职业覆盖度 |